The AI labs are saving you from yourself.
Coding agents are asking more clarifying questions, even when they don’t need to. I think the AI labs are trying to save us from ourselves. Here’s how I read the trend, the picture I draw in my head to make sense of it, and the failure mode I keep walking into when I skip past the questions anyway.
The /loop moment.
The case study is small and a little absurd. I asked Claude Code to put a task on /loop with a thirty-minute interval. /loopisn’t some generic built-in. It is a Claude Code slash command, defined and documented by the same harness that was about to ask me about it. Anthropic ships /loop. Claude Code is the agent the user is talking to. The two are not separate systems.
It still stopped and asked. Did I want it to fire every thirty minutes on the hour, or every thirty minutes from this moment?
The interval is genuinely ambiguous and the question is technically correct. But the agent is asking the user for clarification about a command its own runtime defines. The spec lives inside its own scaffolding. Either default could have been justified by the feature’s own documented intent. It still asked.
That is how far the dial has tilted. Coding agents now stop to ask clarification even on inputs that touch their own first-party surface, the place where the ambiguity could be resolved by the agent looking inward instead of outward. Whatever’s going on behind the scenes at the labs, the visible result is more questions, more often, on lower-stakes inputs.
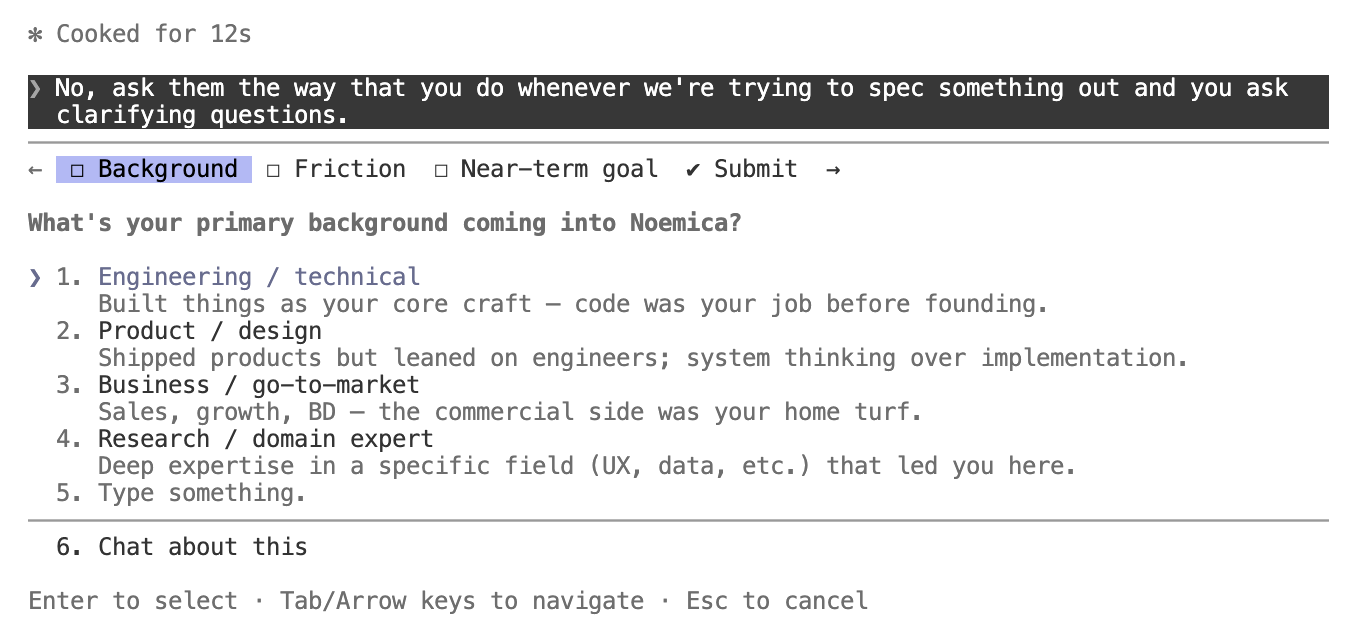
/loop moment, just the same kind of behavior on a different prompt. Claude Code stopping in the middle of work on the noemica codebase to render its interactive options menu rather than pick. This kind of pause is now routine.“Clarifying questions don’t just reduce error. They redistribute blame.”
The blame loop.
Here is the loop I imagine the labs are watching, and responding to:
- The agent receives a prompt with ambiguity in it.
- The agent makes a reasonable guess and runs.
- The output lands somewhere other than where the user expected.
- The user attributes the miss to the agent, not to the prompt.
Once that loop is established, the cheap lever is to ask before guessing. Clarifying questions don’t just reduce error. They redistribute blame. The clarifying question turns an ambiguous-prompt failure into a clarified-prompt success, and it also does a quieter second thing: once you answered the clarification, the outcome is yourspec, not the agent’s guess.
Two things compound underneath the trend:
- People trust coding agents more, so they hand them longer-running tasks.
- Longer-running tasks have more surface for outcome drift, and therefore more chances to miss.
The longer the agent works before delivering, the larger the dissatisfaction footprint when the work lands on the wrong axis. Front-loading the question is the obvious move.
The shape of expectation.
Here’s the picture I draw in my head. Plot the user’s expected outcome against the time the agent has been working.
It rises, not linearly. Logarithmic-like (as is the case with all perception (= noem- 😊)), fast at first, then slower, then it plateaus, and somewhere past about fifty minutes it inverts. Once an agent has been chugging for an hour with no sign of progress, I stop thinking “the answer will be late” and start thinking “the agent is corrupting things while I wait.”
Two lines worth marking, by feel:
- 30 minutes, the medium-horizon line. I am expecting a real result and won’t accept “almost” anything.
- 50 minutes, the long-horizon line. Past this I’m looking for a reason to stop the agent before it makes things worse. The fear isn’t latency. The fear is regression.
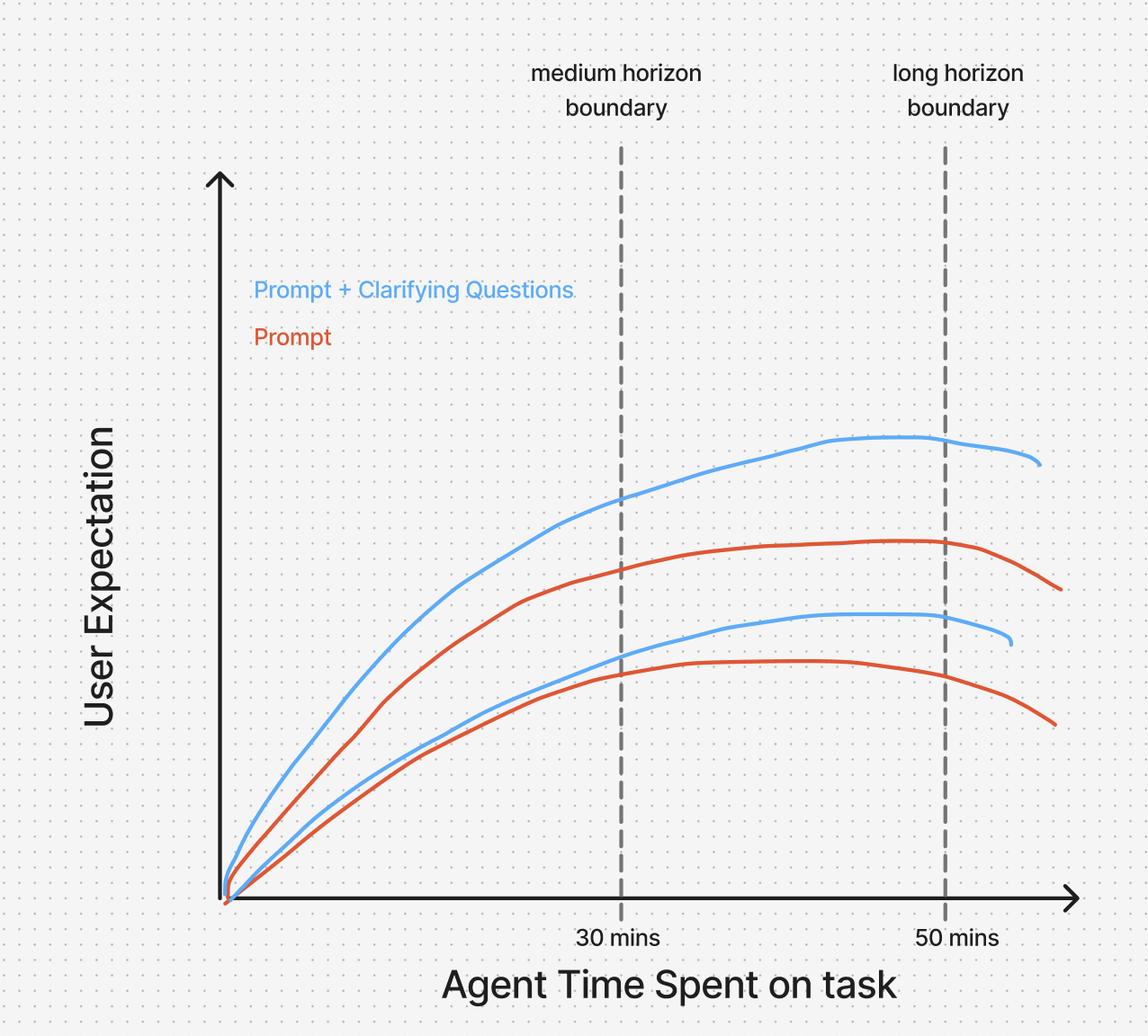
I draw it as not quite symmetric. A delivery that lands too late doesn’t just arrive late, it arrives needing to be undone before the next agent can work on it.
What the question actually buys.
The clarifying question doesn’t just lift the expectation curve. It compresses the range of outcomes, and lifts both ends of the range, not just the ceiling.
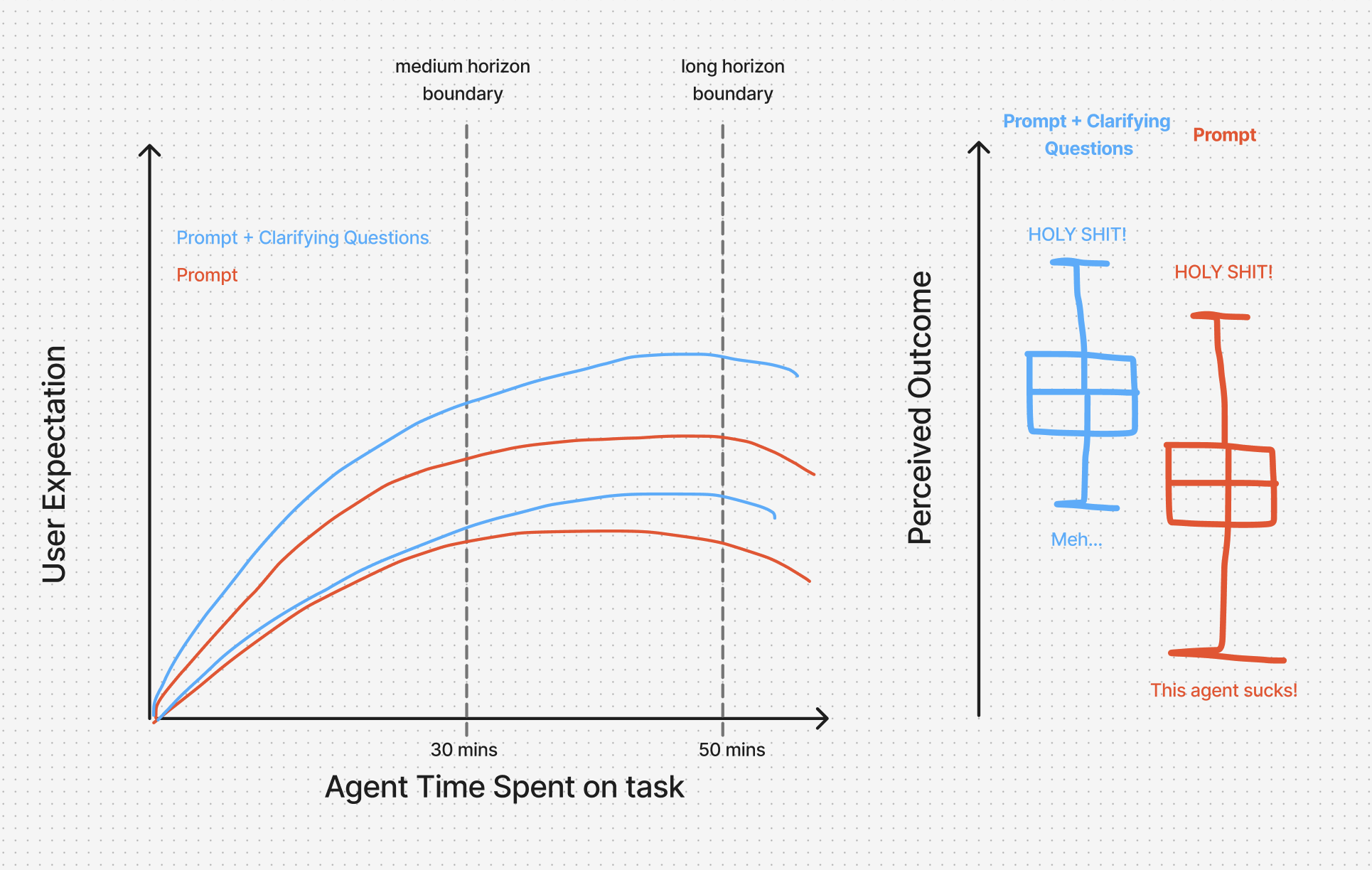
Without clarification: the agent guesses. Most of the time the guess is close enough. Sometimes it’s off by a ninety-degree angle and I find out forty-five minutes in. Best case: “holy shit, it nailed it!” Worst case: “this agent sucks!” Wider range, lower mean.
With clarification: the agent paid a small startup cost, then aligned to what I actually meant. Best case: “holy shit, it nailed it!” Worst case: “meh, not quite what I wanted.” Narrower range, higher median, and a ceiling slightly above the no-question version, because the agent had a real spec to outperform. But most importantly the agent has a much higher minimum, therefore reducing accusations of incompetence.
The asymmetry sits in three places at once:
- The cost of clarifying questions is fixed and small. A few seconds, one click.
- The cost of the wrong foot scales with the agent’s autonomy and the task’s length.
- As both grow, the second cost is always larger than the first. The gap between the blue and red curves widens with time.
That’s the trade, as I read it.
“The clarifying question is a small fixed cost. The wrong foot is a long open one.”
The wrong-foot problem.
The agent can’t tell when it has started on the wrong foot. It can only see what I typed. From its side, every task starts on the right foot, and my expectation curve is climbing the same way regardless of which axis the work is on. Forty-five minutes later the work is wrong, and I don’t get those forty-five minutes back.
The clarifying question is a small fixed cost. The wrong foot is a long open one. That asymmetry is the whole reason the question exists.
… but I still skip them.
This is where the whole argument lands on its face.
Knowing all of the above does not change my behavior. I mash through clarifying questions because I’m in a hurry and I want to keep momentum. I tell the agent to move forward without reading its plan closely. I treat the options menu as a speed bump. I’m not unique in that.
The labs are tilting the dial one way. I, at least, am tilting it the other. The clarifying question is friction I am paying to avoid, even though, by the picture I just drew, I shouldn’t.
There’s a perverse loop in this too. The more false-positive clarifying questions I get, the less I trust them. The less I trust them, the more I mash through without reading, and the more likely I am to miss the one that would have actually changed the outcome. That’s just the nature of a feature like this. You can’t get it perfectly right all the time, and the price of overdoing it is the user tuning out the signal that was meant to help them.
What happens next, when you skip the question on a long-horizon task, is the subject of the next piece. It is the failure mode in this article, played out for real: a coding agent pushed forward without the option to ask, shipping a wrong-axis solution, then spending several more iterations extending the mistake and declaring victory along the way.