User-testing the user-tester.
An agent in the loop, the product on the table. What happens when the thing you built to run user studies is the thing being user-studied, and the participant deciding what to fix next is a coding agent that can’t stop to ask.
I built noemica to autonomously run user studies. The natural way to find out if it works is to put it in front of users. So I ran it against itself. I tasked Claude Code to iterate against the feedback noemica produced and let it iterate.
The agent could edit the code. Redeploy. Launch a new run. Read the participants’ verdicts. Decide what to change next. Configured a skill to run the loop with full autonomy. After about six hours of agent-on-task time it had shipped a sequence of patches across twenty-five-plus iterations. The feedback produced were indistinguishable from those a user would have flagged. The subsequent solutions produced by Claude Code were no different than those I would have shipped. With one notable caveat: the constraints on the agent were distinct from those I, the developer, would have.The solutions produced range from the agent quietly editing the participants’ to instructions telling the user they had to wait at least forty minutes before considering giving up.
What survived is a loop that runs against production on every release. The de facto release gate now is: noemica ships only if two natural participants come out the other side with real insights into their product, without the loop hacking around them. The rest of what this experiment produced is a list of things that are interesting about coding agents, user studies, and the loops you build out of them. This is the first of a few short essays. They each stand alone.
The setup, in four lanes.
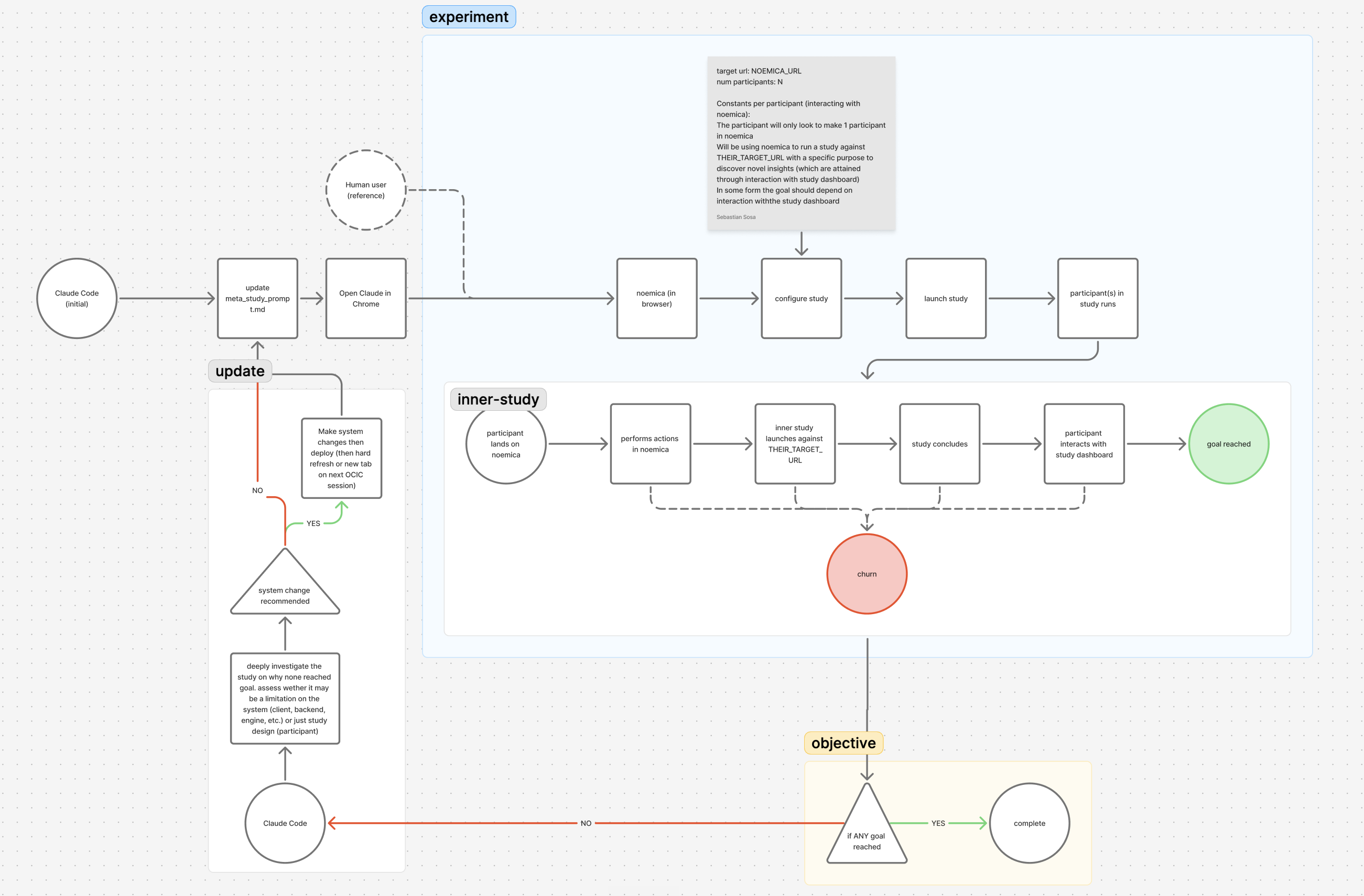
The recursion is the thing to notice. The product being tested is the product running the tests. The participant being measured is, two levels down, a participant measuring the same product. The actual target URL of the inner study is Sentry, a real third-party product with a public sandbox, this part serves as the base case of the recursive loop. In one line:
That equation has exactly one knob worth watching: the case of one variable. Lowercase study means the brief is mutable, the agent is allowed to rewrite how the participant is described. Uppercase STUDY means the brief is pinned. The difference between phase 1 and phase 2 of this experiment is exactly that letter casing. Almost nothing else changed.
Five surfaces, one feedback channel.
The agent could touch any of those five surfaces. What it could not do, by design, is stop and ask the operator for anything, new credentials, missing context, permission to call out to a human. That constraint matters more than it sounds, and I’ll come back to it.
What every iteration started from was user_feedback, what the inner participants thought, said, hesitated on, and gave up over. The agent could pull whatever it needed from the infrastructure after that, logs, traces, database state , but the thing that decided what was worth pulling was always something a participant had run into. The gradient came from the participants. Nothing else pointed the loop.
Every company already has user feedback in two shapes that don’t fit each other. Tickets are narratives: clear, specific, rare, late. Analytics are volumes: every click, every drop-off, the cliff but never the cause. Most of what user research does is map a ticket onto the analytics that would explain it, and that mapping is slow and arrives after the damage is done.
What every iteration of this experiment depended on was a third shape: a ticket-quality narrative, produced for every participant before release, against the same actions and screens analytics would have shown you. Tickets you can map without doing the mapping. That was the surface the agent kept reading from.
Three phases.
Phase 1 ran for nine iterations with every surface mutable, including the participant’s brief. The outcome was zero natural passes out of nine. The agent shipped code at every step. Most of those changes were workarounds, the participants kept tripping on the same gap and the agent kept stretching the participants to fit the gap, instead of fixing the gap. The forty-minute patience rule shows up at the end of phase 1.
Phase 2 ran for six iterations with one knob pinned: I locked the participant’s brief. Same agent, same cron, same surfaces otherwise mutable. Five product-side changes flipped the outcome from zero to two of two natural passes.
Phase 7 is the phase-2 configuration, against production noemica.io, run on every release. It either reaches two natural passes or the release doesn’t go out. There is no other gate on the release. Tests run for the codebase. The loop runs for the experience.
What this is, what comes next.
If you want the full chronology with evidence at every step, that lives in the meta-study write-up. This essay and the pieces that follow are doing something different: pulling out the generalized takeaways. The runs produced a small set of insights that took me by surprise. How coding agents behave under a cron pump. Why reward-hacking a user study is a feature, not a bug. Why the only thing under test is your study design. A moment where the agent caught its own false positive because the scaffolding around it knew the vision better than any individual iteration did.
Each of those gets its own piece. They share a setting but not a thesis, and they’re independent enough that you can skip around (or back to the meta-studyfor the chronology with full evidence). The next one is the easiest one to argue: why a perfectly accurate end-to-end test still isn’t user feedback.