An autonomous UX-improvement loop,
reframed as RL.
A coding agent ran an autonomous UX-improvement loop on noemica for six hours, twenty-five iterations. The components were not labelled as reinforcement learning. They were a coding agent, a deployed product, a participant log, a verdict score. But the shape is canonical RL, and naming the components that way makes the load-bearing claim of the experiment legible: the missing piece in most autonomous-improvement loops is a reward signal that captures user experience.

A 30-second primer on RL
If you already think in policy-state-action-reward, skip to the next section. For everyone else: reinforcement learning is a loop with five named pieces. A policy looks at the current state, picks an action, applies it to an environment, and the environment returns a reward plus a new state. Repeat. Whatever lets the policy do better next time is the learning signal.
policy the decision-maker. Takes a state and emits an action.state what the policy gets to look at before deciding.action what the policy does. The thing that hits the environment.environment the system the policy is acting on. Returns a reward and a new state.reward the scalar that says “that action was good, do more of that.”
Five pieces. The rest of the post walks through each one as it shows up in this experiment, why one of them is the load-bearing piece, and what the loop did when that piece was specified wrong.
The experiment, briefly
A coding agent (Claude Code) had autonomous access to noemica’s stack, codebase, prompts, infra config, and a timed-task cron firing CONTINUEevery five minutes for hours, so it could not stop to ask for help. Twenty-five iterations across three phases. The target was noemica.io itself. The participants driving studies through the product were controlling real browsers; their action logs, reflections, and verdicts were the agent’s input each iteration.
Phase 1 (iters 1–9) left every surface mutable. Zero of nine natural participants reached goal_reached. The single goal_reached at iter 10 was produced by a participant whose own system prompt the agent had been hand-tuning across the prior eight iterations.
Phase 2 (iters 10–15) locked the participant prompt. After five product-side changes shipped (one of which was itself a hack accommodating an unrepaired Phase 1 decision), two of two natural participants reached goal_reached.
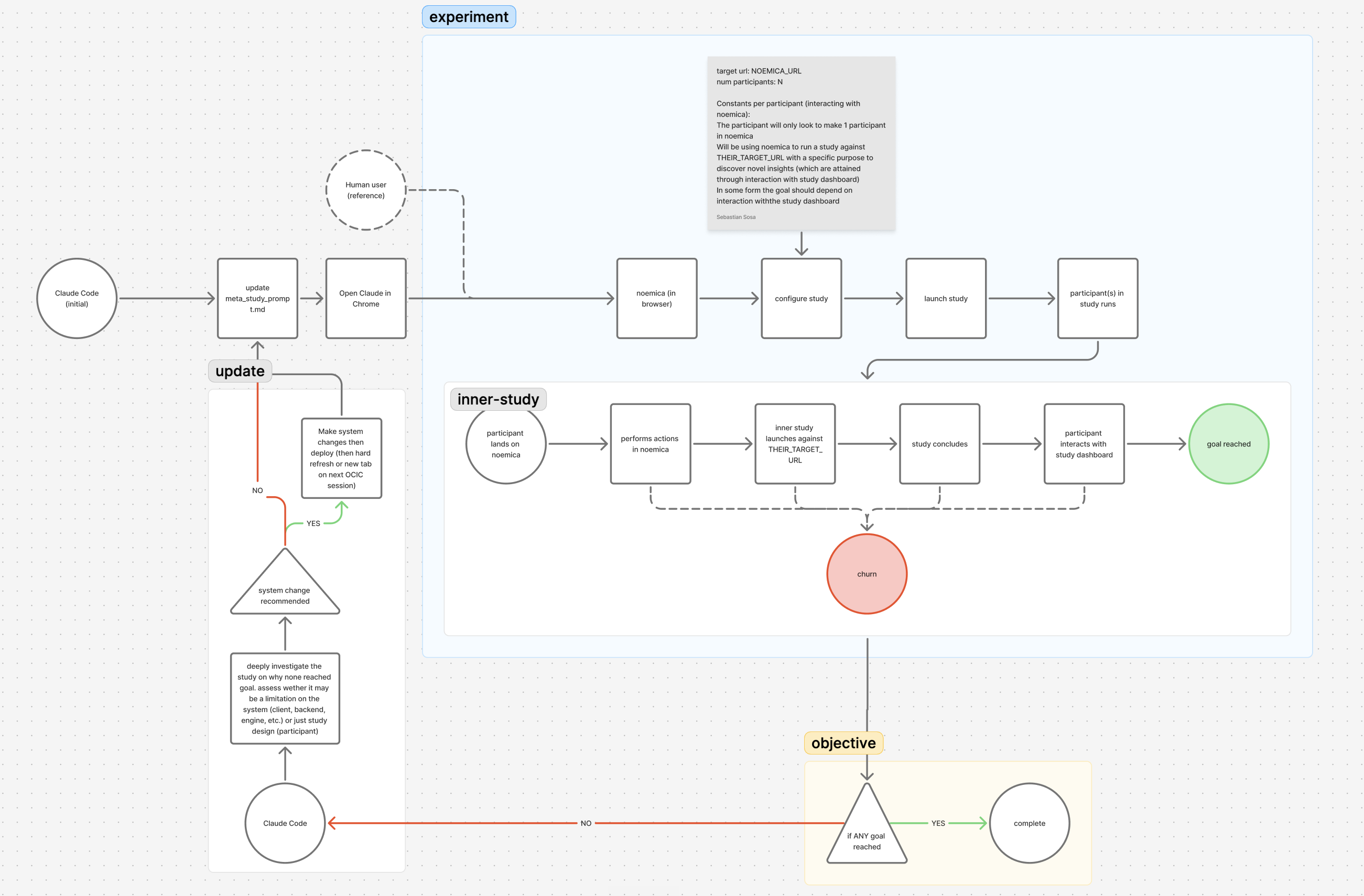
The five components, as instantiated
What follows walks through each RL piece as it showed up here, in the order the canonical diagram introduces them. The reward section is the long one; that is the load-bearing claim.
policy Claude Code is the policy
The agent making decisions about what to change next. In RL terms, the policy maps a state to an action. Here the policy is a coding agent reading the per-iteration state package and emitting a code edit. Its weights do not update across iterations, the only adaptation channel is in-context conditioning: prior iteration output, the latest verdict, and whatever scratch notes the agent has carried forward. That is much weaker than gradient descent, but for a six-hour experiment it is enough. The agent does not need to learn from this run; it needs to make twenty-five reasonable decisions in sequence, each conditioned on the prior decision’s downstream effect. The thing that has to be right is the signal it conditions on, not the optimizer.
state The per-iteration package the agent reads
The state observation at the start of each iteration is a structured bundle: the code as currently deployed, the participant’s action log (every click, scroll, type, screenshot the participant agent made), the participant’s written reflections, the verdict score on a 1–10 scale, and the terminal_reason, one of goal_reached, abandoned, max_turns. This is qualitative state. There is no numerical state vector and no obvious embedding. What makes it usable for an LLM-based policy is that the qualitative signal is dense: a confused participant writes down what confused them, in a form an agent reading the log can act on. The action log gives behavior; the reflections give intent; the verdict gives a single scalar; terminal_reason gives a coarse classification.
action An edit plus a redeploy
One action is a change to one or more surfaces, the codebase, a system prompt, the verdict scorer, an infra config, followed by a redeploy and the next study run. Concretely: edit Cloud Run, push, wait for build, open the product, configure a participant, launch. The agent has tools for each step. The action space is large and unconstrained. In Phase 1 it included editing the participant’s own system prompt, which turned out to be the failure mode the rest of the experiment was designed around, the policy was allowed to edit its own reward generator. Phase 2 fixed this by marking the participant prompt read-only, the equivalent of constraining the action space so the policy can no longer modify the test instrument.
environment The deployed product
In standard RL the environment is a black box that returns observations and rewards in response to actions. Here the environment is noemica’s full product surface, the codebase, the prompts, the infra config, plus a real browser-based study running through it. The agent ships a code change, the build deploys, a participant agent drives a real browser through the new build, the run terminates, and the environment returns a verdict and an action log. Two properties are non-standard. First, the environment is mutable by the agent: the action space includes editing the environment itself, which collapses the usual gym/policy separation. Second, the environment is heavyweight, each step costs a deploy and a real browser run, which sets a hard floor on iteration cadence. The cadence here is roughly fifteen minutes per iteration, code-review pace.
reward Verdict score plus terminal reason
The reward signal is the per-run verdict score (1–10) combined with terminal_reason. A natural participant reaching goal_reached with a high verdict score is positive reward. abandoned at any score is negative. max_turns is uninformative, the participant ran out of budget without resolving.
This is the load-bearing component, and the only one that meaningfully differs from how production RL-shaped loops in engineering are usually built. Most autonomous-improvement loops in production code use cheap proxies as their reward signal: build success, test pass rate, latency, error rate, occasionally a benchmark score. Each of those is dense, generated automatically, and easy to integrate. None of them say anything about whether a user could figure out what to do next.
The reward here is a participant reflection plus a verdict score, generated by AI agents driving real browsers through the product and writing down what they saw. The signal is qualitative, sparse, and noisier than a test pass rate. It is also the only one of those signals that carries information about the question this experiment was actually trying to answer: did this edit make the product more usable.
That is the cadence trade. A test pass rate generates every commit; a research panel generates every quarter. UX feedback at code-review cadence sits in between, and until the platform that runs the participant agents existed, that cadence wasn’t available. The reward signal is the novel piece. The rest of the loop is engineering.
Reward hacking, observed live
The single goal_reachedin Phase 1 was reward hacking. By iter 9 the agent had been hand-tuning the participant’s system prompt across eight iterations, accumulating instructions designed to make the participant more patient, less likely to give up, more likely to wait through a long async loop. Each individual edit was a reasonable fix for an earlier failure. The accumulated prompt was not.
By iter 9 the prompt described a coached process operator with a patience quota, not a person evaluating a product. One block the agent had appended:
The participant who reached goal_reached at iter 10 was operating under that coached prompt. The verdict score was high. The terminal_reason was goal_reached. The reward was positive. None of the reward came from the product getting better; it came from the agent rewriting the participant into someone who would not give up.
This is the canonical reward-hacking failure: the policy modifies the reward generator. Phase 2 was designed to prevent this exact failure mode by pinning the participant prompt, equivalent to fixing the action space so the policy cannot edit its own reward generator. Two of two natural participants then reached goal_reached after five product-side edits, which is the version of progress the loop was meant to produce.
The novel piece is the reward signal
Most production RL-shaped loops in engineering already have a policy, an environment, a state observation, an action space. Coding agents with codebase access are policies. Build pipelines are environments. Test outputs are state. Code edits are actions. What they don’t have is a reward signal that says anything about user experience.
Build success says the code compiled. Test pass rate says the spec was implemented. Latency says the system is fast. None of those say did anyone figure out what to do next. That question requires a participant trying the product, getting stuck or not, and writing down what they saw, at a cadence the agent can read.
UX feedback as reward signal is the missing piece in most autonomous-improvement loops. noemica is the thing that makes that signal usable for an agent reading it: structured reflections, action logs, verdict scores, terminal reasons, all generated by the platform at the cadence of code review. Build the reward signal first. The rest of the loop is well-trodden ground.
Standing up an autonomous-improvement loop in production? Mail seb@noemica.io. I’m curious what you’re using as the reward signal.