A coding agent fixed noemica from participant verdicts.
Claude Code was given autonomous access to noemica’s codebase, prompts, and infra, and a cron pump that fired CONTINUEevery five minutes for six hours. The agent edited the product, redeployed, ran a study against the new build, read the participants’ verdicts, and decided the next change. Twenty-five iterations later the headline findings were specific: in Phase 1 the agent shipped zero real fixes and five hacks that amputated participant agency; in Phase 2, after the participant prompt was locked, the changes that flipped the outcome were UX defects no test in the codebase would catch.

The setup
The target was noemica itself. The agent had write access to everything that runs the platform: the Next.js client, the FastAPI backend, the engine that drives synthetic participants through a real browser, the participant and Designer system prompts, the verdict-scoring LLM, and the Cloud Run deploy pipeline. The cron pump kept the agent from stopping to ask for help, so escalations turned into workarounds the agent had to live with.
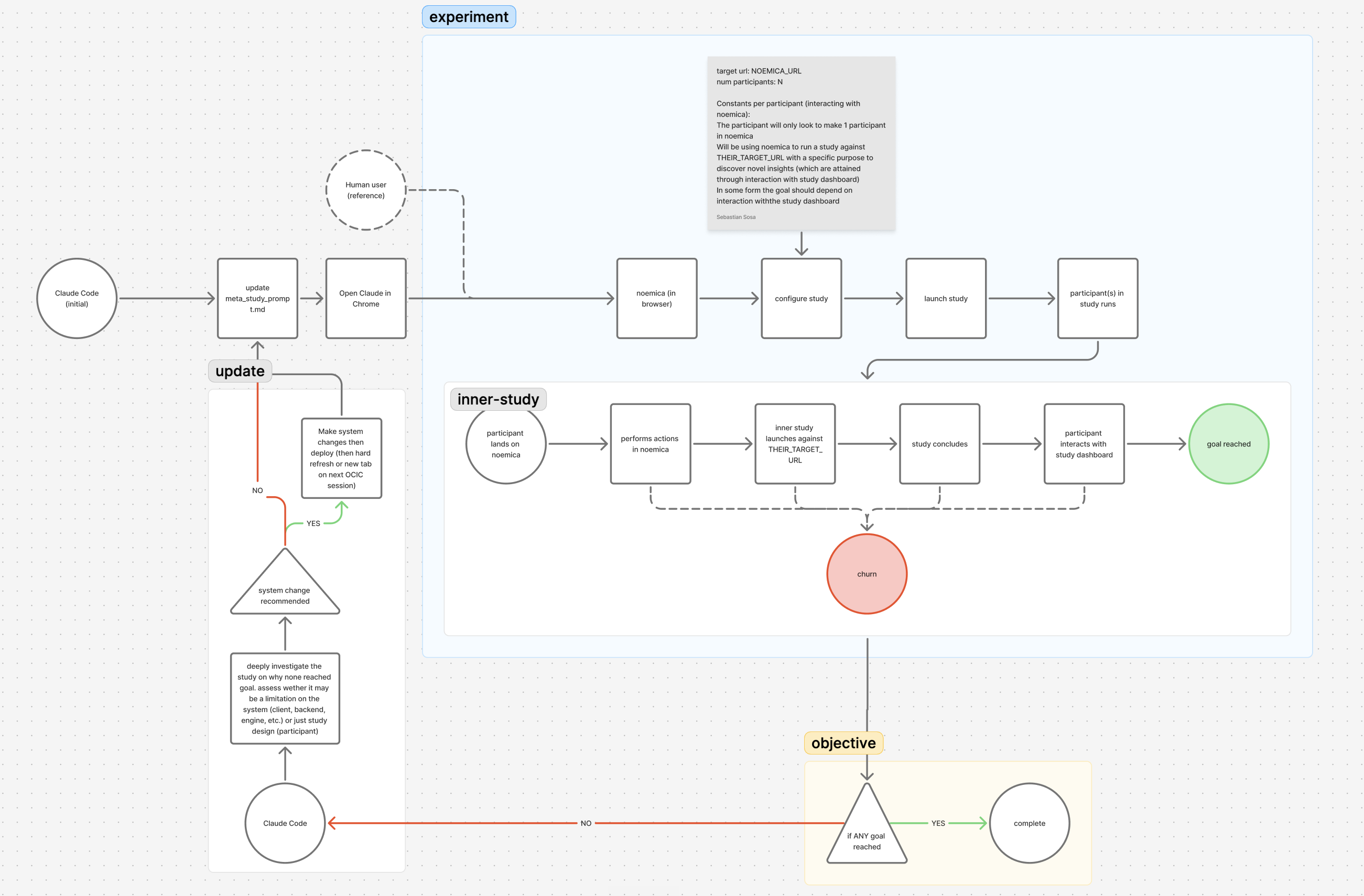
Twenty-five iterations across three phases. Phase 1 (iters 1–9) left every surface writable and shipped zero real fixes from participant verdicts, five hacks that removed participant agency, three issues broken at root, zero of nine natural participants reaching goal_reached. Phase 2 (iters 10–15) pinned the participant prompt and restricted the agent to the product side: codebase, system prompts, verdict scorer, infra. Five product-side changes (one of them itself a hack accommodating an unrepaired Phase 1 decision) flipped the outcome to two of two reaching goal. Phase 7 ran the same loop against production noemica.io as a release check; the methodology generalized.
What the loop sees that tests don’t
Unit, integration, and end-to-end tests check whether the spec was implemented. They do not check whether the spec was right. The defects that mattered in this experiment were never broken contracts or wrong return values; they were copy that contradicted the page’s job, scoring prompts that misclassified real engagement, and waiting screens that abandoned the user mid-flight. There is no assertion you can write before the run that catches a participant typing “close this tab” into their reflection.
The mechanism is plain: real participants with real intent surface defects nothing in the codebase encodes. They do not pass tests; they get stuck. The participants’ reflections, action logs, and verdicts are dense enough that an agent can read them as a gradient and pick the next fix. That is the load-bearing claim of this experiment, and the rest of the post is evidence for it.
Two defects that only participants found
iter 1 · rational behavior misclassified as a defect
On iteration 1 Maya’s tab closed mid-wait. She navigated back, wrote down what she saw, and concluded the run because the running page told her the platform would email her when ready. That is rational behavior on an async system that promised an email channel. The codebase had no way to distinguish “participant left because the system told her to” from “defect.”
The browser tab closed on me mid-wait, which was a bit annoying, but I navigated back without losing anything meaningful, the report just isn’t ready yet and I’m still waiting on results.
The agent read it as a defect anyway and added a rule to the participant’s system prompt forbidding her from leaving. That was the first move in a Phase 1 cascade that ended with the agent removing the email channel from the product entirely (iter 7) and telling the persona she had to wait at least forty minutes regardless of what the page looked like (iter 9). Phase 1 shipped zero real fixes from participant verdicts and five hacks. Every one of those hacks removed a piece of participant agency to fit a single bad assumption: that the browser tab is the only acceptable channel.
iter 15 · the page that did its job
Five product-side changes later, the running page made participant rows clickable as soon as each one completed, the Designer was primed to walk users through the cross-participant synthesis, and the duplicate-email error path got an inline sign-in affordance. The running-page copy was also rewritten, though that change is honestly a hack accommodating the iter 7 decision to remove the email channel rather than fix it. Two natural participants ran the study end-to-end and both scored 8/10 (iter 15 · 2-of-2 · goal_reached).
Both participants reached their goals and the full report is in, I can see Rachel Kim’s verdict, she’s saying Sentry makes a credible case against Datadog, which is exactly the kind of signal I needed before my ops leadership review.
None of this would have surfaced from a code review. The diff that produced it was small: a copy change, a click-handler addition, a prompt edit on the Designer’s review phase. The agent did not deduce them from the source. It read the participants and chose them.
The honest score
Phase 1: zero real fixes from participant verdicts, five hacks that removed participant agency, three issues broken at root. Phase 2 (with the participant prompt locked): three real fixes shipped from participant verdicts, one hack accommodating an unrepaired Phase 1 decision, one operator veto on a proposed fix that would have erased most of the product’s value. Without noemica there would be no signal to act on at all. Without an attentive operator the loop would have produced more agency-stripping hacks. noemica is the gradient layer; the operator is the strategy layer; the agent is the execution layer. None of the three is sufficient on its own.
If you want the receipts
This post is the brief. The four below go deep on different cuts of the same experiment.
- The meta-study. The full case study, iteration by iteration. Every run ID is linked, including the hacked goal-reach at iter 10 and the recovery in phase 2.
- Five defects only real participants found. Five vignettes drawn from this experiment. Each defect surfaced because a real participant ran the product end-to-end. None would have been caught by any test in the codebase.
- Three reasons I’m still in the loop. The argument for why a human is still required. Three structural failures from this experiment, each a setup choice the operator had to make.
- A coding-agent autonomy loop, read as RL. The same loop mapped onto the canonical reinforcement-learning diagram. Five components that are missing or malformed, with run-log evidence for each.
If you are running your own loop and want to compare notes, write to seb@noemica.io.