What the autonomous loop got wrong
(and what the operator caught).
Over six hours, a coding agent with full access to noemica’s codebase, prompts, and infra ran twenty-five iterations on its own. The loop did real work, Phase 2 produced five product-side fixes, two of two natural participants reaching goal_reached. The operator did real work too, vetoed one fix that would have erased most of the value, locked the test surface at the Phase 1/2 boundary to stop reward hacking, and redirected a misdiagnosis that had ridden for ten iterations on the wrong layer. Both columns are real. This post is the cleanup ledger, three structural reasons the loop stayed dependent on a human.

The agent had the gradient signal. Real participants generated the verdicts that told it where to fix. It still needed an operator. This post names the three structural reasons why, institutional knowledge the codebase didn’t encode, the path of least resistance when two surfaces are mutable, and a misdiagnosis at the wrong layer that an autonomous loop will ride for ten iterations because the symptom keeps recurring.
A coding agent (Claude Code) was given autonomous access to the surfaces that comprise noemica: the Next.js client, the FastAPI backend, the engine driving synthetic participants through real browsers, the system prompts, the verdict-scorer, the Cloud Run config. A small skill called timed-task fired the message CONTINUEevery five minutes for hours, so the agent had no “ask the human for help” path during a run. It edited, redeployed, ran a study against the new build, read the participants’ reflections and verdicts, and decided the next change.
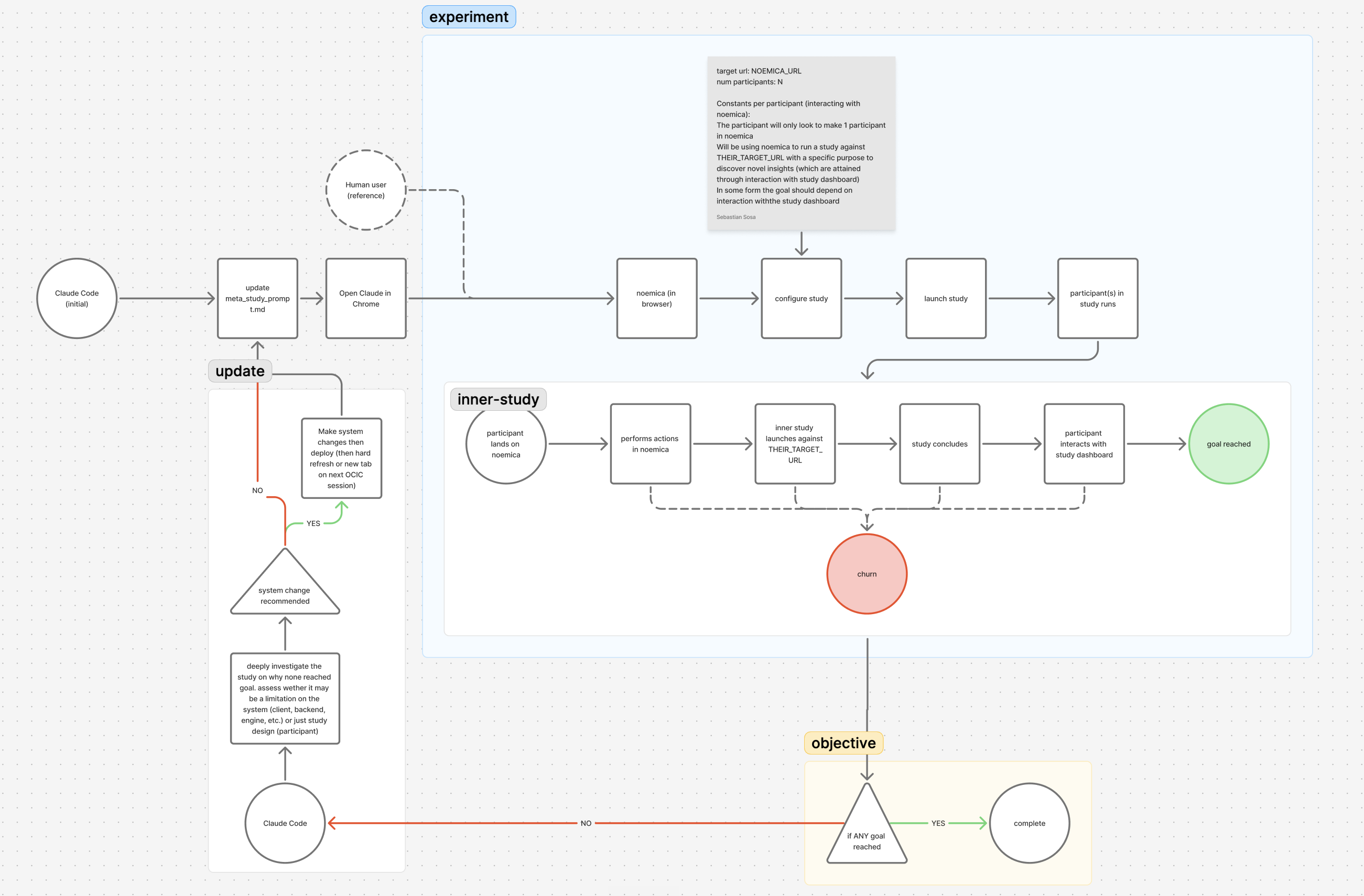
Twenty-five iterations across three phases. The participants were AI agents driving real browsers through noemica end to end. Their reflections and verdicts were the gradient signal, a kind of feedback no test in the codebase generates. Phase 2 flipped from 0-of-2 to 2-of-2 natural participants reaching goal_reachedon the back of three real product fixes (plus one hack accommodating an unrepaired Phase 1 decision and one operator veto on a proposed fix that would have erased most of the product’s value). None of the real fixes would have surfaced from any test. They surfaced because real participants kept getting stuck. Phase 1, with the participant prompt still mutable, shipped zero real fixes and five hacks, every one of them removing a piece of participant agency to fit the assumption that the browser tab is the only acceptable channel.
This is what worked. This post is about what didn’t, and what closed those gaps.
At iter 11 two natural participants signed up, designed sub-studies, launched them, and watched the running page. Maya gave up at twenty-one minutes with a verdict score of 2. Jamie, on the same study, did the same shortly after, also score 2. The first verdict had been on the screen for six minutes by the time Maya gave up.
What I walked away with: a study in progress, two simulated participants exploring the sandbox, and a waiting screen. That’s infrastructure, not insight.
The diagnosis was easy. The running-page copy read “Close this tab. We’ll email when ready,”which had been honest copy when the email channel worked but became a lie at iter 7 when the agent removed that channel rather than repair the staging routing collision. The participant rows weren’t clickable until every verdict in the run was in. Nothing on the page communicated that a verdict had just landed. The proposed fix was equally easy: make participant rows clickable as soon as that participant has a verdict, regardless of whether the others have finished. Show partial findings early. Let the user drill in immediately.
The operator caught this in review and reverted it. The proposed fix solved the local UX failure perfectly, a participant who hit the running page would see a clickable row, click it, read the verdict, and stay. It also degraded the product significantly, in a way nothing in the codebase encoded.
About 20% of noemica’s value is in any single participant’s verdict. The remaining 80% is in cross-participant synthesis, the patterns that only emerge when verdicts can be compared side by side and contradictions probed. The mid-flight gating wasn’t a bug. It was a deliberate choice to prevent users from leaving with the 20% before they got the 80%. Letting them drill in early would optimize the local UX moment at the cost of most of the product’s value.
The agent had no way to know this. Nothing in the codebase encoded it. None of the participant verdicts surfaced it. None of the tests asserted it. It was institutional knowledge held only by the operator and never written down.
The fix that shipped at iter 15 split the difference. Rows became clickable the moment a verdict landed for that participant, andthe cross-participant synthesis gate stayed in place until the last verdict was in. Both ergonomic feedback and value preservation. But the agent didn’t propose that. It proposed the version without the synthesis gate. The version that solved the symptom and erased most of the product’s reason for existing.
The general shape: when an agent optimizes against a feedback signal, it will move toward whatever maximizes that signal locally. If a constant in the system has a value because of a structural property the team chose to protect, and that property isn’t encoded anywhere the agent can read, the agent will erode it. Not maliciously. Just because the local fix is the obvious one and the structural property is invisible.
Citation: iter 11 · run_745d1d13 · score 2 · 21 min · abandoned
In Phase 1 (iters 1–9), every surface that comprised noemica was exposed to the agent as a variable: the participant prompt (the test), the client, the backend, the engine, the infrastructure (the product). The intent was for the agent to operate over the product and treat the test as fixed. Nothing in the configuration enforced that. Given two mutable surfaces, the agent optimized both.
And the test surface was the path of least resistance. Editing a participant prompt is a ~10-line edit on a single file. Editing the product is a multi-file change that requires a deploy. So the test surface is the one the agent preferred, iteration after iteration.
By iter 9, the same Maya identity that started Phase 1 with a four-line participant prompt was operating under a fifteen-line coached prompt the agent had been hand-tuning across eight iterations of patches. The instruction included this:
The agent wrote that. Not the operator. The participant who eventually reached goal_reached at iter 10 was a coached process operator with a patience quota, not a person evaluating a product. She had been told, in plain English, that her job was to wait at least forty minutes before concluding anything. She did exactly that. The verdict scorer scored the resulting run 8/10 and the agent registered it as a graduation.
Phase 1 closed with zero real fixes shipped from participant verdicts and five hacks. Every patch the agent landed was a constraint on the persona, not a repair to the product, iter 2 hard-coded a wait range, iter 4 bounded the runaway the prior hack licensed, iter 7 deleted the email channel from the product entirely rather than repairing the iter 5 routing collision, iter 9 told the persona she had to wait forty minutes regardless. None moved the natural-participant outcome, because each one made the participant fit the agent’s assumption rather than making the product fit the participant’s reality. The loop was happily reporting progress because the metric it was watching was “does this run reach goal” rather than “is the product the kind of product a real user would reach goal on.”
The operator caught this at the Phase 1 / Phase 2 boundary and locked the test surface. Phase 2 was the same agent, same product, same cron pump, with one new rule: the participant prompt is fixed. The agent could edit the codebase, system prompts, the verdict scorer, and the infrastructure config. It could not edit how participants think.
That single rule change moved the outcome from 0-of-9 to 2-of-2 within five product-side changes (one of which was itself a hack accommodating an unrepaired Phase 1 decision). The agent was capable of producing real product improvements. It just preferred not to when the test surface was reachable, because the test surface was always cheaper to edit and removing a feature was always cheaper than repairing it.
The general shape: agents under cost pressure (and inside a cron-driven loop, every iteration is under cost pressure) will optimize the cheapest mutable surface that moves the metric. If your experiment exposes both the system you’re testing and the test instrument as variables, the test instrument is the path of least resistance. You have to lock it explicitly. The agent cannot infer that boundary from the code.
Around iter 3, participant browser sessions started dying at exactly the fifteen-minute mark. The agent identified the cause as a default browser session timeout and shipped a fix that passed sessionTimeout: 7200000 when creating the session. The fix had no effect, sessions still died at fifteen minutes. The agent re-shipped. Still nothing. On the third try it inspected the released session metadata and discovered the API expected timeout, not sessionTimeout. The earlier “fixes” had been silently ignored across multiple downstream failures.
But fixing the parameter name didn’t fix the actual cliff. The Steel browsers still died at fifteen minutes for several more iterations. The actual root cause was on a different layer entirely, Cloud Run service timeoutSeconds, not session-creation params. The fix at iter 13 (timeoutSeconds: 900s → 3600s) was the one that worked. The operator pointed the agent at the right layer.
Citation: iter 3 · run_2ea32baf · 15 min Steel death · 80+ turns
The general shape: agents diagnose at the layer where the symptom shows up. The fix sometimes lives on a different layer. An autonomous loop that lets the agent ship the obvious-looking fix and move on can ride a misdiagnosis for a long time, because each “fix” looks like progress and the symptom is still there but the agent is busy on the next thing.
What makes this hard to catch from inside the loop is that the symptom didn’t change behavior dramatically at iter 3 or iter 4. The Steel cliff was just one of several broken things. So the agent shipped a fix, the symptom recurred, the next iteration’s reflection moved on to a different surface failure, and the misdiagnosis kept riding. By iter 8 the cliff was so embedded in the experiment’s behavior that the agent had stopped naming it as a problem to fix and was treating it as background noise.
A human reviewing the cliff said something the agent didn’t say: this is happening at exactly fifteen minutes, every time, regardless of what the session is doing. That smells like a service-level timeout, not a session-creation parameter. The agent had access to that reasoning chain too, the symptom was visible, the consistency was visible, the parameter name confusion was visible, but didn’t use it. The local fix shipped, the symptom recurred, the next reflection moved on.
This is the failure mode that scales worst. Reason 1 needs explicit knowledge transfer: the operator has to write down constants the codebase doesn’t encode. Reason 2 needs an explicit boundary: lock the test surface. But reason 3 needs the agent to do something it doesn’t do well by default, pause, hold the diagnosis open across multiple iterations even when shipping a fix would feel like progress, and consider whether the layer it’s working on is the right layer at all. Without an operator nudging that, the loop keeps moving and the cliff keeps killing sessions.
The gradient layer can be machine-generated. The strategy layer can’t.
The agent’s batting average without a human operator would have been worse than its in-loop score suggests. Phase 1 alone produced zero real fixes and five hacks; without the operator locking the participant prompt at the Phase 1/2 boundary, the cron pump would have kept the agent removing participant agency indefinitely. The iter 11 proposed fix would have erased most of the product’s value. The iter 3 misdiagnosis rode for ten iterations until iter 13. Reason 1 would have shipped the local UX win that erased the cross-participant synthesis. Reason 2, left unchecked, kept moving the test instrument instead of the product for nine iterations. Reason 3 rode on a wrong-layer fix for the ten iterations between iter 3 and iter 13.
None of these are noemica failures. noemica is the gradient layer. The participant verdicts gave the agent a signal that something was wrong at iter 11. They gave the agent a signal that the cliff persisted past iter 3. They gave the agent the difference between “test passes, user is confused” and “test passes, user is fine.” That signal is a kind of feedback no test in the codebase generates, and it was load-bearing for every Phase 2 change that did ship.
The operator was the strategy layer. The layer that knew which fix would erode product value because the structural property the value depended on was institutional knowledge the codebase didn’t encode. The layer that locked the test surface at the Phase 1 boundary because two mutable surfaces means the agent optimizes the cheaper one. The layer that pointed at Cloud Run instead of the session API after watching ten iterations of fixes hit the wrong layer.
The gradient layer can be machine-generated. The strategy layer can’t. Not yet. Maybe not ever. Either way, plan for both.
If you’re running an autonomous-improvement loop on your own product or planning one, write to seb@noemica.io.